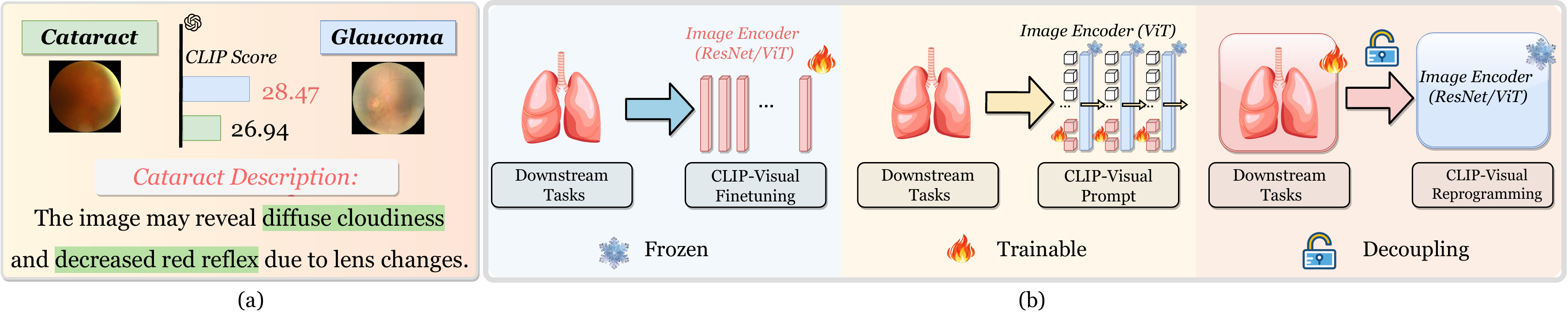
Recent advances in vision–language models (VLMs) such as CLIP have demonstrated strong generalization across natural-image domains. However, adapting these models to biomedical imaging is non-trivial: full-model fine-tuning is computationally expensive, while medical data are often scarce and exhibit subtle, fine-grained inter-class differences, making parameter-efficient adaptation particularly critical.
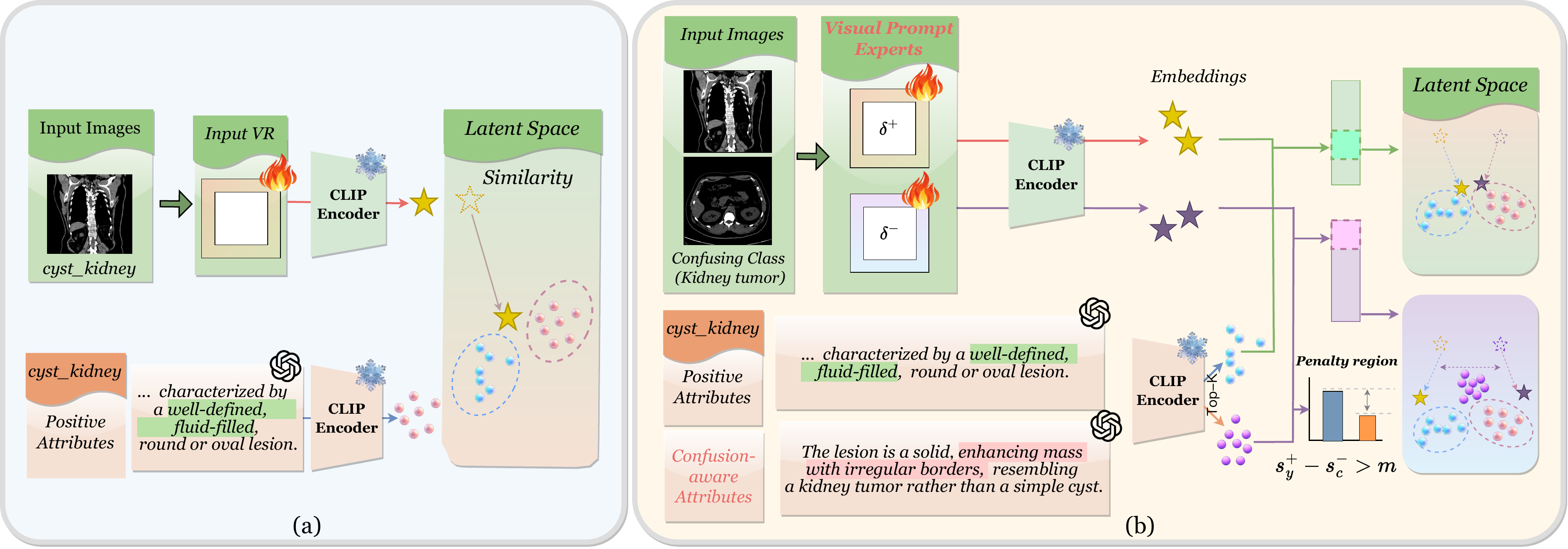
Visual Reprogramming (VR) offers a parameter-efficient alternative by injecting learnable perturbations into the input space, but existing VR approaches for VLMs mainly focus on positive class prompts and overlook confusing negatives, leading to miscalibrated predictions in fine-grained medical scenarios.
We present BioMedVR, the first VR-based framework for biomedical imaging, enabling few-shot adaptation of pretrained VLMs through compact learnable VR modules. To mitigate class confusion, we introduce a Confusion Minimization Mechanism that leverages LLM-generated confusion-aware attributes together with a Confusion-Suppression Loss to explicitly reduce false-positive alignment. The designed Mixture-of-Prompt Experts (MoPE) combines a positive expert for main-class discrimination and a negative expert for confusion suppression, balanced via adaptive gating.
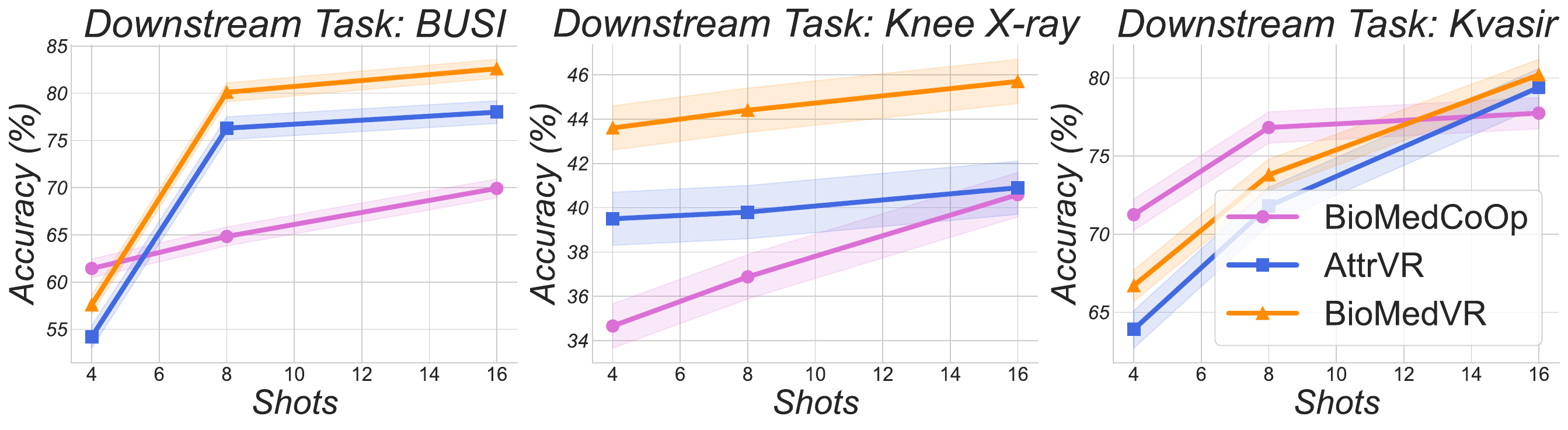
Extensive experiments on 18 datasets—11 biomedical and 7 natural-image benchmarks—demonstrate that BioMedVR achieves superior accuracy and generalization, effectively bridging VR and VLMs in biomedical domains.